绪论:初识机器学习
什么是机器学习
一个程序从经验E中学习,解决任务T,达到性能量度P,当且仅当有了经验E后,经过P评判,程序在处理任务T时的性能有所提升。
简单来说,通过投喂数据,教会机器使用算法解决问题。
监督学习
数据集包括“正确答案”,根据样本学习进行预测。
问题包括分类与回归
无监督学习
给算法大量无标签数据,从中分析出某种结构。比如对数据进行聚类
单变量线性回归
模型表示
回归问题:根据之前的数据预测出一个准确的输出值
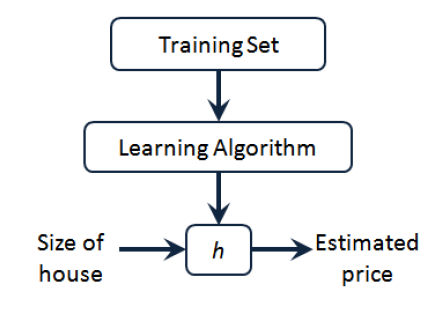
如图所示为预测房屋价格算法的流程,将训练数据集投入学习算法,输出一个函数 h(意为 hypothesis 假设),该函数可根据输入的房屋面积预测售价。
上述问题中有可能的 h 表达方式为:
只含有一个特征变量 x,因此该问题被称为单变量线性回归。
代价函数 - Cost Function
上一小节我们知道了函数 h 的表达式,但是如何确定两个参数呢?
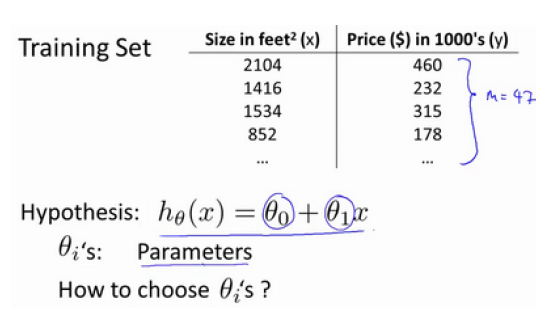
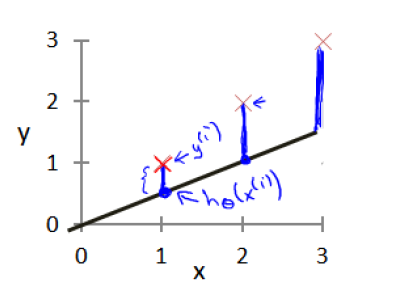
例如预测房价,使用预测函数,可以预测数据集外房屋的售价。但是首先该函数一定要适用于已知数据,而参数决定了我们得到的函数相对于训练集的准确程度,如下图所示,预测值(直线)与实际值(X)的差距就是建模误差(modeling error)
我们的目标就是通过调整参数,使得预测函数能拟合更多数据,从而使代价函数(Cost Function)最小:
可以看出代价函数为建模误差的平方和,m 为训练集中实例的数量。
还有其他的代价函数可以选择,但平方误差代价函数是解决回归问题的常用手段。
代价函数的直观理解

目标是使代价函数最小,根据代价函数 J 的三维图像,可知存在一点,在该点的两个参数的取值可使整体代价函数最小,可通过该图进行直观理解。
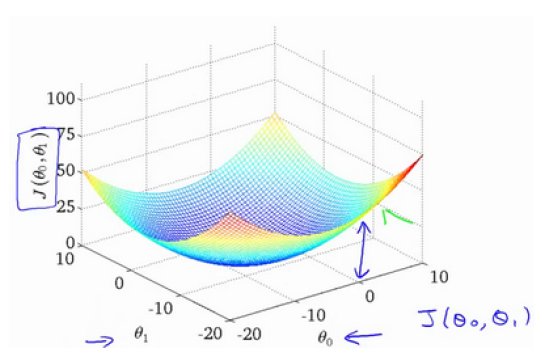
但是如果每次都通过画图看点来找最小值就太麻烦了,并且某些数据难以进行可视化,所以需要有效的算法来自动找出使代价函数 J 最小的参数θ。
梯度下降 - Gradient Descent
梯度下降是一个用来求函数最小值的算法,此处可用来求代价函数 J 的最小值。
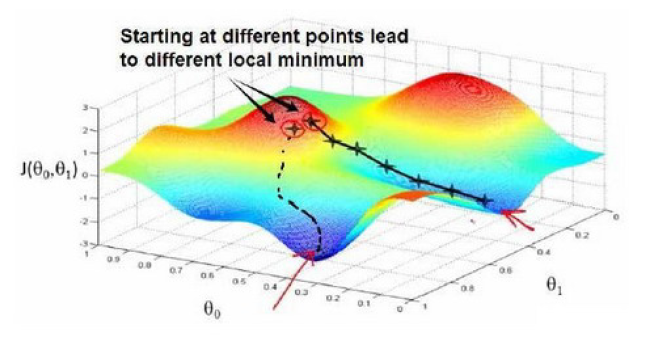
随机选取参数作为起始点,计算代价函数,然后下一组寻找能使代价函数下降最多的参数(就如同山顶下山,环顾四周,选择最陡峭下降最快速的方向),直到周围的参数无法使代价函数下降,此时达到了一个 局部最小值(local minimum)。
上述公式为 批量梯度下降(batch gradient descent),其中 α 是学习率(learning rate),即控制代价函数的下降速度。
在运算过程中,同时更新参数是梯度下降的一种常用方法。
梯度下降的直观理解
公式理解
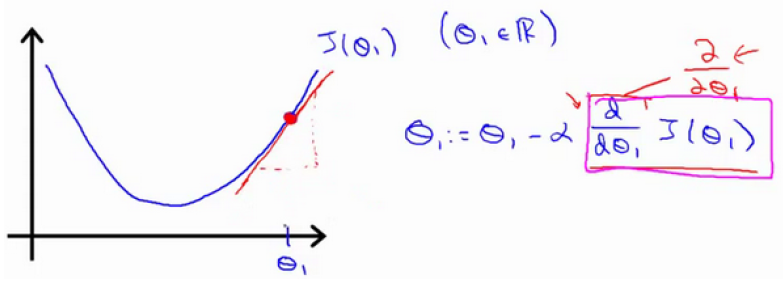
实际上求导操作是计算该红色直线的斜率,该直线为正斜率,所以新的 θ1 更新后等于 θ1 减去一个正数乘以 α 。
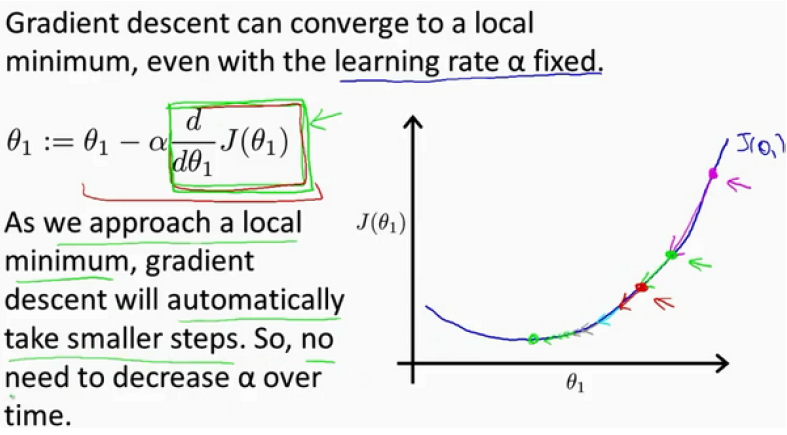
如果 θ 初始化时就在最低点,意味着已经在局部最优点,切线导数为 0,θ 的值不会再改变,所以梯度下降算法其实什么也没做,这也是为什么保持学习速率 α 不变,梯度下降依然可以收敛到局部最低点,而不需要边训练边改变参数。
实际上在接近最低点的过程中,导数值自动的变得越来越小(斜率越来越小),所以梯度下降的幅度也会减小,所以没有必要另外减小 α 。
α 的取值
如果太小了,即学习速率太小,结果就是只能这样像小宝宝一样一点点地挪动,去努力接近最低点,这样就需要很多步才能到达最低点,所以如果太小的话,可能会很慢,因为它会一点点挪动,它会需要很多步才能到达全局最低点。
如果太大,那么梯度下降法可能会越过最低点,甚至可能无法收敛,下一次迭代又移动了一大步,越过一次,又越过一次,一次次越过最低点,直到你发现实际上离最低点越来越远,所以,如果太大,它会导致无法收敛,甚至发散。
梯度下降的线性回归
了解了梯度下降算法,与之前线性回归想结合解决问题。
将梯度下降应用到线性回归当中,关键在于求出代价函数的导数,即:
最后梯度下降算法改写为:
批量梯度下降的意思在于,每一步的求和运算,都用到了所有的训练样本,当然也有其它类型的梯度下降法,不是“批量”型的,不需要考虑全部数据集。